Este post corresponde al primer módulo del roadmap: Foundations + Arquitectura Hexagonal, donde el objetivo no era cubrir herramientas, sino sentar las bases de cómo quiero pensar y diseñar sistemas de pruebas durante el año.
Una de las preguntas más comunes cuando se habla de automatización de pruebas es: ¿Qué pruebas debemos automatizar?
La respuesta clásica tiende a ser: “las que son repetitivas, consumen bastante tiempo y son críticas para el negocio”. El problema aparece cuando esa respuesta se interpreta como “todo es crítico”, y se intenta automatizar absolutamente todo.
Es en ese punto donde las pruebas E2E dejan de ser pocas, enfocadas y estratégicas, y se convierten en suites enormes que intentan cubrir todos los casos de uso. El resultado suele ser el mismo: ejecuciones lentas, alto costo de mantenimiento y una inversión considerable de tiempo y recursos para obtener retroalimentación tardía.
Ahora imagina que tu framework de pruebas está diseñado de tal manera que puedas validar edge cases (errores de índice, validaciones de negocio, flujos inválidos) en segundos, sin levantar un navegador y sin depender de una herramienta específica. Que puedas probar la lógica de tus escenarios de forma aislada y rápida.
Eso es parte de lo que aprendí este primer mes del roadmap de aprendizaje que estoy siguiendo, donde estoy aplicando Arquitectura Hexagonal a un framework de pruebas.
Durante el 2026 estaré profundizando en arquitectura hexagonal aplicada a testing, así como en distintos aspectos del aseguramiento de calidad que he utilizado de forma parcial, pero que necesito dominar con mayor profundidad, y otros que aún no he tenido oportunidad de aplicar, como contract testing y chaos engineering. Si quieres conocer por qué elegí esta arquitectura, sus conceptos base y el alcance completo del roadmap, puedes leer el post inicial donde lo presento:
Roadmap 2026. Test Architecture: 12 meses de aprendizaje continuo
El concepto general de aplicar la Arquitectura Hexagonal es: Lograr separar el qué se hace del cómo se hace.
El problema: tests que no escalan
Hoy en día, uno de los patrones más usados para la automatización de pruebas es Page Object Model (POM). Tomemos el siguiente ejemplo simplificado:
class HomePage:
def __init__(self, page):
self.page = page # ← Dependencia directa de Playwright
def click_blog_link(self):
self.page.locator("#blog-link").click() # ← Locator hardcodedPara alguien que comienza en automatización, este código es válido y funcional. Sin embargo, presenta varios problemas estructurales:
- el Page Object depende directamente de Playwright,
- los selectores están embebidos dentro de la lógica.
A corto plazo esto no es un problema. Pero conforme el número de pruebas crece, empiezan a aparecer fricciones: migrar a otra herramienta implica reescribir la mayoría de los Page Objects; un cambio en un selector obliga a buscar y modificar múltiples archivos; y, quizá más importante, la lógica no puede probarse sin un navegador real.
Esos problemas pueden mitigarse con buenas prácticas dentro de POM, pero cuando el framework crece y los requerimientos del SUT cambian, el patrón deja de ser suficiente como base arquitectónica.
La propuesta: Arquitectura Hexagonal
A fines de 2025, buscando una forma más robusta de organizar mi código de pruebas, decidí aplicar Arquitectura Hexagonal. No como reemplazo de POM, sino como una capa superior que me permitiera desacoplar la lógica de negocio de las herramientas de automatización.
En teoría, esto me permitiría construir un framework más mantenible, más flexible ante cambios de tecnología y con la capacidad de probar escenarios sin depender de un entorno E2E completo. En la práctica, la implementación fue menos trivial de lo que esperaba. Conceptos como el Principio de Inversión de Dependencias y la correcta definición de contratos tomaron tiempo en ser internalizados antes de reflejarse correctamente en el código.
Con esta idea en mente, el siguiente paso fue aterrizar estos conceptos en código.
Aplicación: llevando Arquitectura Hexagonal a un framework de pruebas
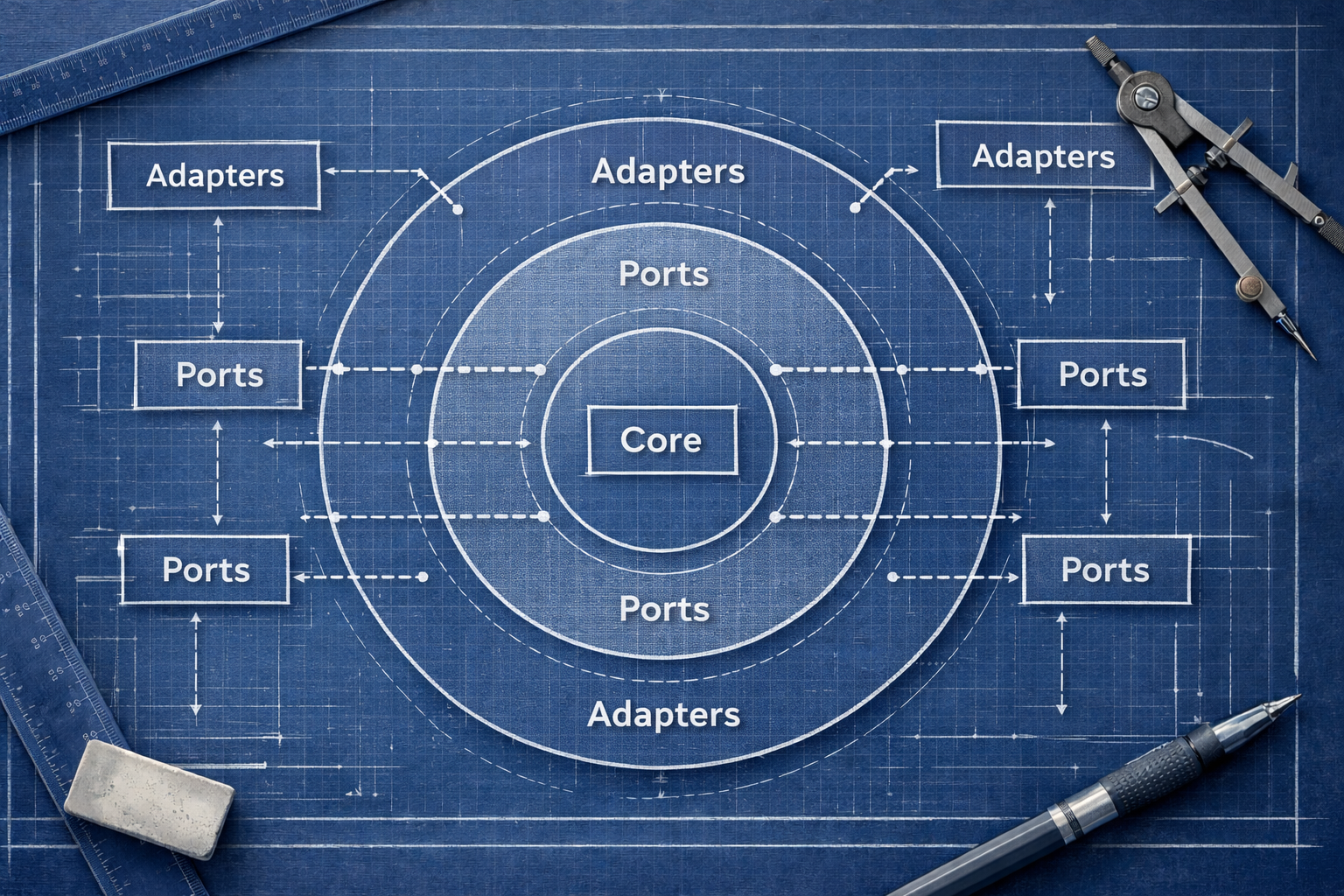
Quizás recuerdes el diagrama de Arquitectura Hexagonal del post donde expliqué lo que aprendería este mes.
El siguiente diagrama muestra cómo ese enfoque se aplica a un framework de pruebas: los Scenarios viven en el core, dependen únicamente de Ports, y distintos tipos de tests reutilizan la misma lógica cambiando únicamente los Adapters.
Figura 1. Arquitectura Hexagonal aplicado a un framework de pruebas
Si pensamos en un framework de pruebas como una aplicación que interactúa con una página web, el diagrama anterior sirve como mapa para entender donde vive cada responsabilidad. Con eso en mente, entonces podríamos definir el Port como la interface que determina cómo nos comunicaremos con la página usando un navegador. El BrowserPortentonces va a determinar qué interacciones son posibles mediante el navegador.
Para ello tendremos una clase BrowserPortque tendrá métodos como Click, o Navigate to, pero sin específicar cómo se hace, ya que eso no le interesa al Port, ese es trabajo del adapter. En el caso de Python, nos valdremos de Abstract Base Class (ABC) para la creación de esta Interfaz formal.
from abc import ABC, abstractmethod
class BrowserPort(ABC):
@abstractmethod
def click(self, locator: str) -> None:
"""Hacer click en un elemento"""
passPor ejemplo, BrowserPortdetermina que se puede hacer clicks en elementos, pero no le interesa el cómo se hace. En otras palabras, el Port es el contrato de capacidades para en este caso específico, usar un navegador para interactuar con la página web. Al hacerlo de esta manera estamos aplicando el Repository Pattern, que nos permite tener separación de responsabilidades.
Scenarios como lenguaje del negocio, no del framework
Ahora, hablemos de los Scenarios. Los scenarios nos muestran la intención que hay detrás de las acciones del usuario al utilizar el SUT. Escribir los métodos con nombres que reflejen qué quiere hacer el usuario hace que el código deje claro qué hace el usuario y qué espera al usar la página web.
Un ejemplo sencillo de qué se espera ver en un Scenario:
HomePageScenario.verify_featured_post_is_shown(): Lenguaje de negocio vs.page.locator('[data-testid="featured-post"]').is_visible(): Implementación
Un Scenario no conoce las herramientas que se están utilizando, el Scenario sabe la manera en que el usuario interactúa con la página web porque entiende las capacidades otorgadas por el Port. Podríamos decir que es el núcleo del dominio de pruebas. Aquí es donde encontraremos la lógica del negocio. La ventaja de separar la lógica del negocio con la lógica de pruebas la podemos encontrar en el siguiente ejemplo:
def get_all_post_titles(self) -> list[str]:
"""
Obtiene los titulos de todos los posts listados en la página de blog.
Returns:
list[str]: Lista de titulos en el orden en que aparecen.
"""
return self._browser.get_all_nested_texts(
self.post_card.postCardContainer,
self.post_card.postCardTitle
)La función get_all_nested_textses una capacidad definida en el Port. El Scenario no sabe si usé Playwright, WebDriver IO, o Selenium. Solo sabe que tiene la capacidad de obtener todos los textos anidados porque el Port le permite hacerlo.
Inyección de dependencias usando fixtures
En este punto pudiera surgir la pregunta, ¿Qué pasa si en un test case necesito interactuar con diferentes Scenarios para probar un flujo E2E? En el caso específico de Pytest nos valemos de los fixtures. Los fixtures en pytest son funciones decoradas que se utilizan para tener un entorno consistente al momento de ejecutar pruebas. Al ser reutilizables y modulares, son ideales para implementar la Arquitectura Hexagonal porque no necesitamos crear instancias directas de los Scenarios.
import pytest
@pytest.fixture
def browser_port(page: Page) -> PlaywrightBrowserAdapter:
"""
Fixture que provee la implementacion concreta del BrowserPort.
"""
return PlaywrightBrowserAdapter(page)
@pytest.fixture
def navigation_scenario(browser_port) -> NavigationScenario:
"""
Fixture que provee el scenario con la dependencia inyectada.
"""
return NavigationScenario(browser_port)En el ejemplo anterior tenemos el fixture browser_port que retorna el adaptador de Playwright que usa las capacidades definidas por BrowserPort. Ahora, el fixture de navigation_scenario nos permitirá realizar las acciones de la lógica del negocio usando el Adapter de Playwright. Si el próximo mes decido agregar Selenium como Adapter, solo necesito agregar los fixtures correspondientes y podré ejecutar mis pruebas sin necesidad de estar modificando Scenarios. La lógica de negocio se mantiene, solo cambia la herramienta usada.
Cuando no necesitas un navegador para probar un escenario
Quizá de lo más destacable que aprendí este primer mes fue la teoría introducida en el capítulo 4 del libro Architecture Patterns with Python. Ahí se habló del Service Layer para tener una separación de responsabilidades y cómo en diferentes sistemas, es utilizado para mantener contenida la lógica del negocio, y que permitía tener tests que pudieran probar esa lógica con datos que se guarden en memoria.
En el caso del framework de pruebas esto abrió una posibilidad: Poder simular interacción con mi blog mediante fakes. ¿Y qué valor tiene eso? Bueno, cuando decidí probar ese aprendizaje del libro (ojo, que no estaba en el plan original del roadmap) tuve que crear FakeBrowserAdaptereste Adapter tiene paridad de métodos con el Browser Port. Después de agregar los tests correspondientes, 6 en este caso, al ejecutarlos me llevé una sorpresa. Solo 0.02 segundos de tiempo de ejecución.
Dado que este Adapter trabaja con un DOM simulado del Blog, toda la información está disponible en memoria, no es necesario levantar un navegador. Todo esto fue posible por la clara separación entre Qué se puede hacer del Cómo se hace.
Probar estados límite sin pagar el costo de E2E reales
¿Qué tipo de pruebas son las que se hicieron con FakeBrowserAdapter? Architecture Patterns with Python introduce un concepto que fue nuevo para mi: Tests edge-to-edge estos tests son tests que prueban cómo el framework responde ante Errores de Índice, Excepciones y otras fallas que se puedan encontrar en el SUT. ¿Los errores son los esperados? ¿Esa excepción es la correcta? Ese tipo de preguntas se contestan al ejecutar este tipo de tests. Por ejemplo, este es el fixture usado para simular que no tengo posts en mi blog:
@pytest.fixture
def fake_browser_empty():
"""
FakeBrowserAdapter sin posts (blog vacío).
"""
dom_state = {
BlogPageLocators.blogPageTitle: {
"text": "Blog",
"visible": True
},
PostCardLocators.postCardContainer: {
"count": 0,
"visible": True
},
f"structured_data:{PostCardLocators.postCardContainer}": []
# No hay post cards
}
return FakeBrowserAdapter(dom_state)De esta manera, simulo ese raro caso en que no hay contenido en la página Home. La ventaja de utilizar el Adapter Fake es que al no levantar el navegador, se pueden ejecutar este tipo de pruebas en milisegundos, permiten determinar qué tan resiliente y confiable es el framework de pruebas al interactuar con el SUT.
Pero sobre todo, permiten evitar caer en la trampa de querer tener pruebas E2E que intentan validar cada rincón del SUT en lugar de enfocarse en los casos de uso reales. Esto no significa eliminar la necesidad de tests E2E reales; estamos redefiniendo cuándo y por qué usarlos.
Algo importante a recordar es que, independientemente de la corriente de pensamiento sobre estrategias de testing, las pruebas E2E siempre deberían ser numéricamente menores. La implementación Fake nos ayudará a cumplir con ese objetivo.
Documentar decisiones no es un hábito automático
Algo adicional que vale la pena comentar, es que en este proyecto estoy buscando aprender no solo de código, sino también de cómo se deben ir tomando decisiones importantes para el desarrollo de un sistema. En este caso, empecé a crear documentación, específicamente Decisiones Arquitectónicas Registradas (ADRs). Cada decisión “importante” se ha registrado en su archivo individual. Al momento, para el mes de enero registré tres decisiones importantes:
- Selección de Arquitectura Hexagonal como patrón arquitectónico para el framework de pruebas.
- Convención para nombrar locators en el código.
- Agrupar locators que aparecen en diferentes lugar del Blog en archivos comunes.
Probablemente sean pocos ADRs tomando en cuenta lo que se implementó. Los ADRs relacionados con locators nacieron como resultado de tener un estándar a lo largo del repositorio. Aunque el Blog es un SUT simple y pequeño, tener este tipo de decisiones documentadas son bastante valiosas en proyectos más grandes y complejos, permitiendo tener un registro de por qué se hacen las cosas de cierta u otra manera.
En caso de que estés interesado en conocer el razonamiento usado y cómo se implementaron esas decisiones, puedes revisar el README.md en la carpeta de documentos en el repositorio.
https://github.com/ignaciops/test-architecture-learning/blob/main/docs/architecture/README.md
Este proceso de documentación también expuso otra realidad: aprender el patrón no es un proceso lineal.
Aprender el patrón requiere fricción
Es muy fácil decir que el código dentro de Arquitectura Hexagonal separa el Qué se hace del Cómo se hace. Pero en la práctica, tomó varias semanas el que pudiera internalizar esa separación. Y sobre todo, dejar de lado la costumbre de “yo escribo mi código de esta manera”. Todavía estos días pasados cuando estaba implementando las funciones para un Scenario, caía en utilizar funciones de Playwright en vez de las capacidades establecidas por el Port.
Pero ahora que enero está por finalizar, soy consciente al momento de escribir una línea de código en este proyecto. La auto-pregunta constante de “¿esto rompe la separación?” me acompaña. Y aunque desearía que lo pudiera hacer de manera automática, al menos me permite estar al tanto de que el código que escribo refleje esa filosofía.
Y sobre todo, no todo lo bueno viene de los happy paths. Los beneficios que ví de la aplicación de los principios de service layer y los tests edge-to-edge me ayudó a abrir el panorama de cómo se pueden probar las cosas. Esa capacidad de tener feedback rápido de cómo reacciona el sistema aporta tranquilidad de que el framework funciona hasta cierto punto, como se espera.
Costo inicial vs simplicidad del SUT
Ahora, no todo es miel sobre ojuelas. La realidad es que para un blog simple como el mío, aplicar Arquitectura Hexagonal al framework de pruebas es un overengineering brutal. Probablemente dediqué más tiempo a tener las bases del framework que el tiempo dedicado a crear el Blog. Sin embargo, para un Framework de pruebas que soportará múltiples SUTs a lo largo de 12 meses y que necesitará capacidades de interactuar con APIs, probar rendimiento, contratos y otras cosas más parece ser una inversión razonable. Así que si has leído hasta este punto, te invito a volver para el mes de julio, donde haré una retrospectiva de mitad de año para ver si valió la pena la implementación o no.
Otro punto a tener en cuenta, es que implementar Fake Adapters no es algo sencillo. Para empezar, el Adapter debe tener paridad de métodos con el Port. Pero quizás la mayor inversión que se le dedica a la implementación es la complejidad conceptual que implica crear un Fake. En el caso del Blog, era necesario simular el estado del DOM, por ejemplo, ¿Qué pasa al hacer click en un link de navegación? ¿Cómo se simula esa acción para tenerla en memoria? Ese tipo de cosas me tomó tiempo el entender cómo hacerlo e implementarlo. Para un sistema con reglas complejas, la inversión de tiempo para tener Fakes es razonable.
El principio es reutilizable, la arquitectura no siempre
La realidad es que uno de los pain pointsde muchos patrones para pruebas E2E y de UI automatizadas tiene que ver por no tener una buena separación del Qué se hace del Cómo se hace. Yo he visto de primera mano buenas implementaciones de Page Object Model donde se logra una buena abstracción y separación de la lógica del negocio de la lógica de las pruebas. No es algo tan común, pero existe. Obviamente cada patrón tiene sus pro y sus contras, pero el principio detrás de la Arquitectura Hexagonal y otros patrones de arquitectura de software sigue siendo válido
Cerrando Enero
Dejando de lado el código, creo que lo que más ha cambiado ha sido mi mentalidad. Enfocarme en mejorar me ha llevado a que mi enfoque cambie de: Necesito un “framework que funcione” a un “sistema que puede evolucionar” es con lo que me he quedado.
Trabajar con ese enfoque, permite que los sistemas y proyectos futuros empiecen con una base sólida, pensando en el futuro: mi futuro yo que tendrá que mantener el sistema, mis futuros colaboradores que tendrán que tocar mi código, mis futuros usuarios que tendrán confianza en la herramienta que les estoy proveyendo.
Probablemente si empezara Enero otra vez, simplificaría la implementación de algunas herramientas, como el Fake Adapter. Me esforzaría por documentar cosas que vayan surgiendo adicionalmente al roadmap de aprendizaje (para que quede claro que es un nice-to-have y un extra). Pero sobre todo, no pensar que si algo parece fácil, será fácil implementarlo. No me confiaré nuevamente en ese aspecto.
Febrero me espera con APIs, FastAPI, Testcontainers y la siguiente capa de abstracción. Nos vemos el próximo mes.
Si quieres seguir el progreso o contactarme, encuéntrame en:
- Repositorio: GitHub
- LinkedIn: ignaciops
- Twitter/X: @ignaciopsdev